发布时间:2026年03月11日 作者:aiycxz.cn
近日,中国移动研究院撰写的论文“Hardware-Algorithm Co-Design for Robotic Edge Intelligence: CIM-Optimized CNN Architectures with Adaptive Kernel Scaling”(《面向边缘智能机器人的软硬件协同设计:CNN卷积神经网络的存算一体架构优化方案》),在第52届国际计算机体系结构研讨会(ISCA 2025 Workshop)发表。该研究聚焦存算一体技术与人工智能算法的协同优化,为机器人的边缘智能场景提供了性能跃升的新路径。
近年来,卷积神经网络(CNN)被广泛应用于机器人目标检测、视觉导航等任务。然而,传统机器人依赖的冯·诺依曼架构处理器存在“存储与计算分离”的先天局限——数据在存储单元与计算单元间频繁搬运,不仅产生延迟,还会消耗大量能量,严重制约机器人的计算性能与续航能力。存算一体技术通过在存储单元内直接完成计算,突破了冯·诺依曼架构的瓶颈,能大幅提升算力和能效水平,成为解决上述问题的关键技术方向。
基于以上考虑,论文提出一种面向存算一体架构的卷积神经网络优化算法,通过引入多分支参数结构、利用大卷积核替代级联小卷积核并结合结构重参数化策略,增加AI模型与存算一体芯片的适配度,从而大幅提升AI模型推理速率与精度,加速存算一体技术在机器人领域的落地应用。
 图1 论文首页
图1 论文首页论文通过采用混合卷积核设计策略,在网络浅层使用小卷积核提取细节特征,保障模型推理精度;在后续网络层级利用大卷积核替代级联的小卷积核结构,减少计算层级,提升模型在存算一体芯片的推理效率。
此外,论文把多分支参数结构引入卷积神经网络,通过在模型训练阶段将大卷积核并联一个小卷积核分支,提升卷积层特征学习能力,从而提升模型推理精度,并在模型推理阶段通过结构重参数化技术将多分支参数无损合并为一个卷积层,降低模型推理计算复杂度。
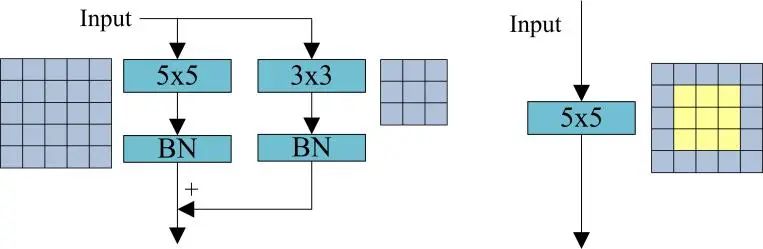 图2 原始卷积和结构重参数化后模型结构示意图
图2 原始卷积和结构重参数化后模型结构示意图实验数据显示,基于混合卷积核(图3中mix)和多分支参数(图3中SRp)优化后的ResNet50系列网络模型在存算一体芯片的平均推理速率提升40%、精度提升1.5%。
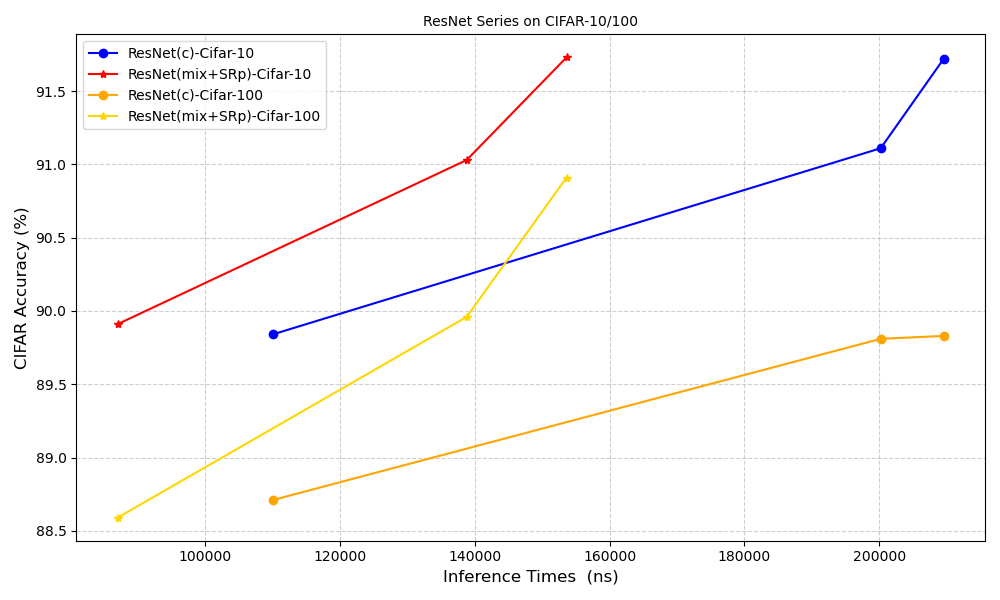 图3 ResNet18/34/50 优化前后推理时延-精度图
图3 ResNet18/34/50 优化前后推理时延-精度图下一步,中国移动研究院将持续深耕在存算一体芯片、软件、算法、应用等领域的创新研究,加快推进存算一体芯片在端、边、云等应用场景的规模化应用落地,为构建更智能、高效的算力基础设施贡献力量。

 限时优惠
限时优惠.png) 论文选题
论文选题.png) 论文专区
论文专区.png) 作业
作业.png) 实习就业
实习就业.png) 长文
长文.png) 写作小说
写作小说.png) 答辩PPT
答辩PPT.png) 范文样例
范文样例 爆款文案
爆款文案.png) 公众号文章
公众号文章.png) 公众号标题
公众号标题.png) 文案优化
文案优化.png) 文案续写
文案续写.png) 文章大纲
文章大纲.png) 文案扩写
文案扩写.png) 文案缩写
文案缩写.png) PPT大纲
PPT大纲.png) 论文大纲
论文大纲.png) 中英文翻译
中英文翻译